[TALEND] data migration 작업 유형
이번 포스팅에서는 Talend 활용법과 더불어 Data Migration 작업을 수행하며 마주한 여러 ETL 시나리오 별 작업 유형에 대해 얘기해보려고 한다. 테이블의 성격이나 작업의 요구 조건에 따라 크게 세 가지의 방식으로 구분되었다.
첫번째는 제일 간단하고 쉬운 유형인 소스의 전체 데이터를 타겟 시스템에 이관하는 케이스이다. 이미 여러 다른 포스팅을 통해 이 유형을 다루었다. 제일 많은 케이스인 table-to-table 이관 및 file-to-table 이관에 해당하는 Job의 예시는 다음 사진을 참고하자.


상세 내용은 다음 링크를 참고하면 될 것이다.
2020.03.30 - [TALEND] - [TALEND] Excel 파일 DB 업로드 하는 방법
[TALEND] Excel 파일 DB 업로드 하는 방법
1. tFileInputExcel 컴포넌트를 생성한다. -> 팔레트에 직접 타이핑 하거나 우측 컴포넌트 섹션에서 찾을 수 있다. 2. tFileInputExcel 컴포넌트를 클릭하여 다음의 설정을 해준다. 1) Read excel2007 file for..
doneisbetterthanperfect.tistory.com
2020.03.30 - [TALEND] - [TALEND] A DB 데이터를 B DB 테이블로 이관하는 방법
[TALEND] A DB 데이터를 B DB 테이블로 이관하는 방법
TALEND 를 사용하면 매우 쉽게 하나의 DB의 테이블 전체 데이터를 다른 DB로 이관할 수 있다. 나는 Oracle DB 의 한 테이블 전체 데이터를 MySQL DB로 이관해보겠다. 1. 우선 적당한 이름을 주어 새로운 J
doneisbetterthanperfect.tistory.com
전체 데이터를 이관하는 경우는 보통 as-is 구조와 to-be 구조를 거의 동일하게 가져가는 케이스가 많다. 다만 as-is로 관리되던 시스템에 쌓인 데이터 양이 많을 경우 이관 속도가 오래걸릴 수 있다. 이때는 다음 링크에 상세히 설명되어 있는 병렬 및 순차적 작업 수행 방법에 대한 포스팅을 참고하면 도움이 될 것이다.
2020.12.30 - [TALEND] - [TALEND] 병렬/순차적 프로그램 실행
[TALEND] 병렬/순차적 프로그램 실행
이번 포스팅에서는 하나의 Job을 여러개의 subjob으로 구분하여 병렬로 수행하는 방법과 여러 개의 job을 순차적으로 수행하는 방법을 알아보자. employee 데이터를 가진 employee 테이블의 데이터는 위
doneisbetterthanperfect.tistory.com
두번째 유형은 이미 타겟 시스템에 데이터가 존재하는 케이스이다. 경험 상 이러한 케이스를 만난다면 그 원인은 크게 두가지 이다. Data Migration이 필요하다는 것은 대대적인 시스템의 재구축이 이루어지는 상황일 것이다. 즉, 이전까지 사업을 운영하면서 생성된 다량의 데이터들을 한번에 옮기는 것이 불가능한 경우가 많다. 따라서 여러 번에 걸처 데이터를 이관해야 하기 때문에 N차 이관이 이루어지는 일정의 경우 1차 이관 이후부터는 타겟 시스템에 어느정도의 데이터가 미리 쌓여있을 것이다. 두번째 케이스는 to-be 시스템이 이미 구축되고 난 후 해당 시스템에 추가로 데이터를 이관하는 경우이다. 이때 타겟 DB에 존재하는 데이터는 운영 중인 데이터일 것임으로 이 경우는 데이터 이관 작업 시 혹시라도 발생할 수 있는 데이터의 손실 등에 특히 주의해야 한다.
두번째 유형의 경우 Talend의 대표 컴포넌트라고 볼 수 있는 tMap 컴포넌트를 통해 소스와 타겟의 두 PK를 기준으로 타겟 시스템에 존재하지 않는 데이터만을 소스 시스템에서 가져와 이관하는 방식으로 작업을 수행할 수 있다. 다음 링크를 통해 상세한 작업 흐름을 살펴볼 수 있다.
2020.11.30 - [TALEND] - [TALEND] 다른 DB 테이블의 데이터 비교 (ORACLE - MARIA)
[TALEND] 다른 DB 테이블의 데이터 비교 (ORACLE - MARIA)
Talend를 사용하여 아주 쉽게 서로다른 DB의 두 테이블 데이터를 비교해보자. 두 테이블 모두에 있는 데이터를 추출해볼것이다. 과정은 다음과 같다. 1. InputDB1: oracleDB 테이블 가져오기 2. InputDB2: mar
doneisbetterthanperfect.tistory.com
마지막 세번째 유형은 두번째 유형을 통해 타겟 테이블과 중복되는 데이터를 식별할 수 없는 경우이다. 이 경우는 보통 테이블 자체에 PK라고 할만한 key가 없거나 mariaDB나 mysql의 경우 auto_increment 속성의 PK만이 존재하는 경우이다. auto_increment PK는 데이터 입력시 자동으로 부여되는 PK로 해당 PK로 타겟과 소스의 데이터 동일 여부를 구분할 수 없는 경우가 많다. 경험 상 이러한 케이스의 테이블은 특정 날짜를 기준으로 데이터를 선별하여 이관하였다. 즉, 1월 5일에 1차 이관이 이루어졌다면 2차 이관이 진행되는 1월 15일에는 해당 테이블의 경우 1월 5일 이후 데이터만 fetch하여 타겟에 이관함으로써 중복 데이터가 이관되는 것을 방지하는 방식이다. 이 경우 매번 날짜를 기억해두고 변경해야 한다는 번거로움이 있다. 이런 번거로움을 줄이기 위해 나는 다음과 같은 방식으로 Job을 만들었다.

위와 같은 흐름으로 Job이 수행된다는 것을 확인하고 본격적으로 각 컴포넌트 별 설정 내용을 살펴보자.

tMsgBox로 해당 Job을 실행할 때 마다 현재 진행할 이관 차수를 입력하게 한다. 여기서 입력받은 차수 데이터를 뒤에서 살펴볼 subjob에서 사용할 것이다. tMsgBox로 문제없이 입력값을 받으면 tFileInputExcel 을 시작으로하는 subJob이 실행되도록 OnComponentOK로 두 subjob을 연결해준다.


tFileInputExcel 컴포넌트로 읽어오는 파일의 데이터는 왼쪽과 같다. 이관 작업 수행일자를 가지고 있는 파일로 여기서 읽어오는 데이터는 세번째 subjob에서 조건 쿼리를 만들때 사용될 것이다. 위 예시에서 두 개의 날짜 데이터가 추가되어 있는 것을 보면 이번 작업이 3차 이관임을 알 수 있다. 또한, tFileInputExcel 설정의 세부사항을 주목하자. tMsgBox로부터 입력받은 차수 데이터에 -1을 한 값을 Header로 가지고 있다. 유저가 3이라는 이관 차수를 메세지 박스에 입력하면 우리는 엑셀 파일의 처음 두 칸 (3 - 1)까지를 header로 취급할 것이다. 그리고 그 후 하나의 날짜 데이터만 읽어오면 되므로 Limit값을 1으로 설정하였다.
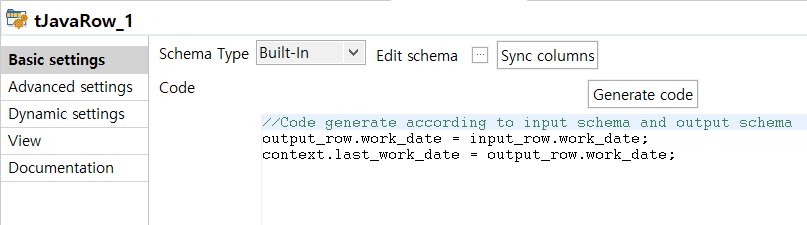
tJaveRow를 통해 엑셀로 가져온 데이터를 Job 내부에서 제약없이 사용할 수 있는 context 변수에 넣어주는 작업을 하고 있다. 마지막으로 tJavaRow를 사용하기 위해서는 반드시 output 성격의 컴포넌트가 필요하기 때문에 tLowRow를 연결하여 두번째 subjob의 설정을 마쳤다.

본격적으로 소스 테이블에서 데이터를 가져오는 쿼리를 살펴보자. 앞서 보았던 두번째 subjob에서 context 변수에 저장해 둔 last_work_date 변수를 쿼리의 where 조건에 추가하여 해당 일자 이후의 데이터만 가져오는 쿼리를 작성하였다. 이러한 방식의 동적 쿼리를 만드는 것은 아래 포스팅에 좀 더 상세히 나와있으니 참고하면 된다.
2021.04.07 - [TALEND] - [TALEND] 동적 쿼리 만들기
[TALEND] 동적 쿼리 만들기
이번 포스팅에서는 매우 유용한 컴포넌트 몇 가지를 바탕으로 동적 쿼리를 생성하는 방법을 알아보자. 우선 이번에 처음 살펴볼 tFlowToIterate 컴포넌트는 input 데이터를 한줄 한줄 읽어 전역 변수
doneisbetterthanperfect.tistory.com
이제 거의 작업이 완료되었다.

tMap에서 소스와 타겟 테이블을 매핑할 때는 별다른 data transformation 작업을 추가하지 않았다. 하지만 out2를 주목하자. order_date 칼럼만 out2로 가져오고 있다. 이는 3차 이관 당시 max(orderDate) 값을 구하기 위해 필요한 작업이다.
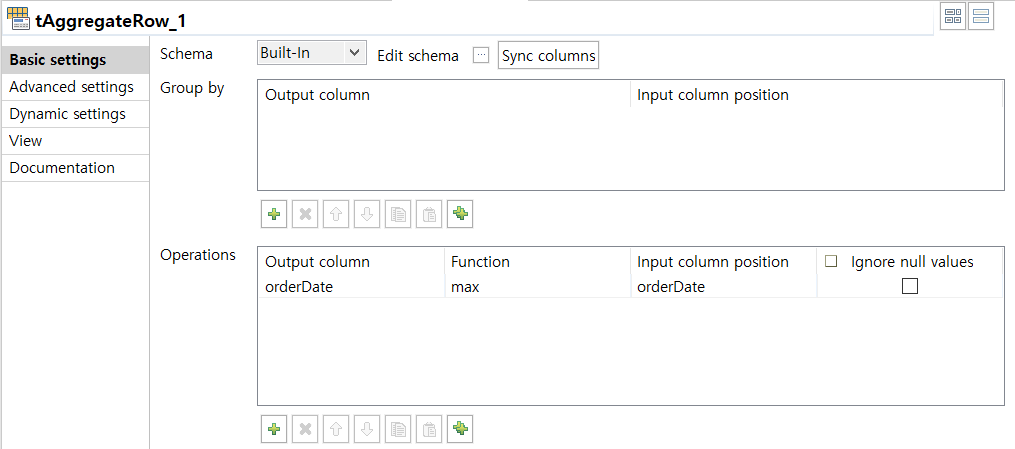
tAggregateRow 컴포넌트로 out2로 가져온 orderDate 칼럼의 max 값을 구할 수 있다. 이제 이 max(orderDate)를 동일한 excel 파일에 기록해보자.

3차 이관 작업이 끝남과 동시에 작업 당시의 max(orderDate)의 값을 가져와 두번째 subjob에서 사용한 동일한 excel 파일에 date 데이터를 기록해놓을 것이다. 이제 이 데이터는 3차와 같이 4차 이관 작업 시 소스 데이터를 가져오는 쿼리를 작성하는데 사용될 것이다. tFileOutputExcel로 데이터를 입력할 때 몇가지 주의할 점은 기존 파일을 유지한 채 신규 데이터만 추가하는 것이므로 Append the exist file, Append the exist sheet 옵션을 체크해주고 X와 Y의 절대위치를 적절히 입력해주어야 한다는 것이다.
이런 방식으로 PK가 없는 세번째 유형의 Data Migration 작업을 보다 쉽고 덜 까다롭게 진행할 수 있다. 내가 실무에서 주로 경험한 유형을 이렇게 크게 세 가지로 나눌 수 있다. 이 포스팅이 많은 도움이 되었기를 바란다.